Extracting Data From PDFs and Other Unstructured Documents
5 min. read
5 min. read
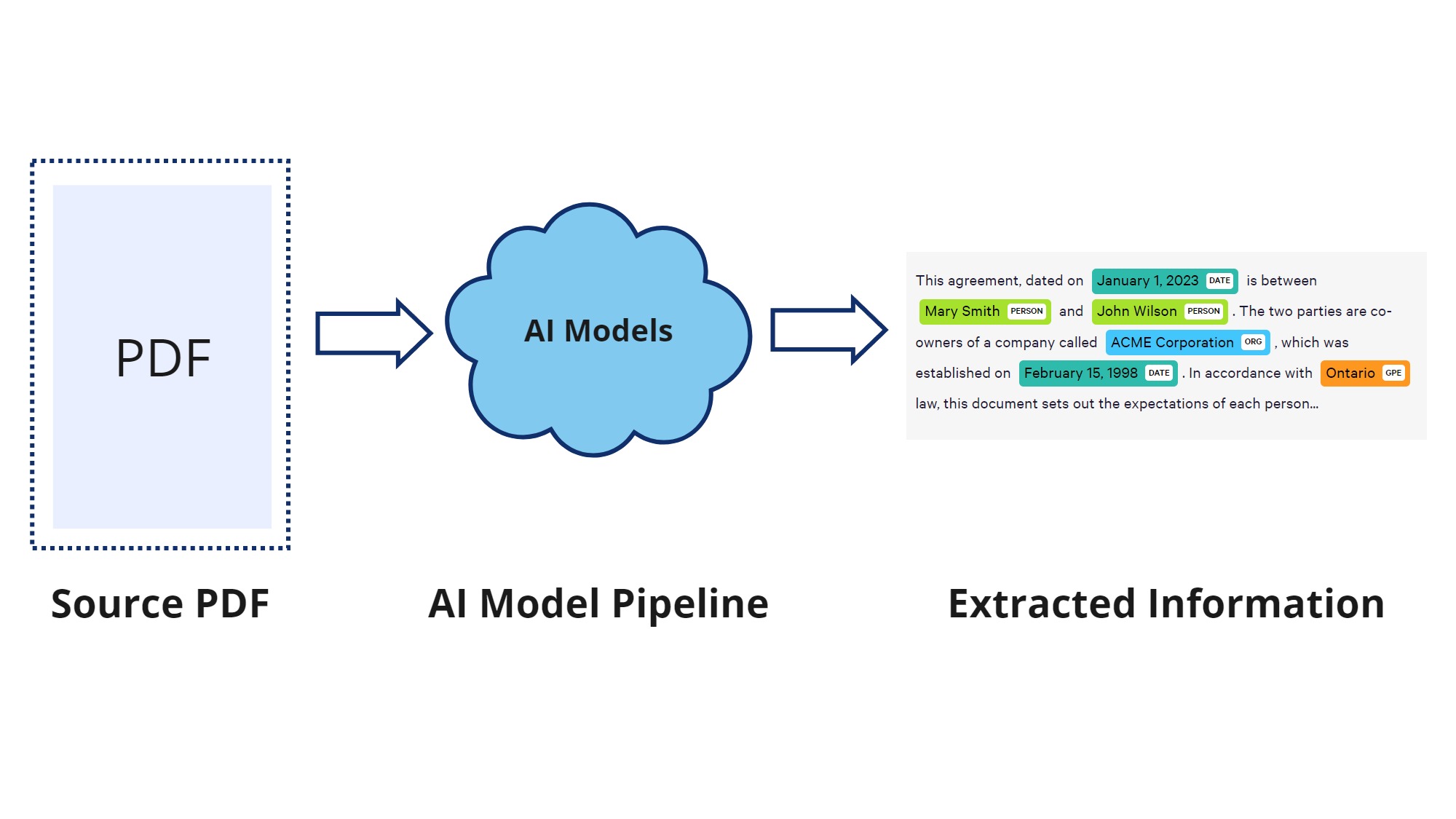
If your organization is looking to speed up mundane tasks like extracting information from PDFs, emails, text messages, and other unstructured documents, this article will walk you through the basic concepts on how it can be achieved. While I focus mostly on PDF documents, similar concepts can be applied to any type of document, whether it be a Word document, text file, email / text messages, or even audio recording transcripts.
PDF is an acronym for ‘Portable Document Format’, and is the go-to document format for sharing documents digitally. If you create a document in Word, and you want to share it, sharing the actual Word document may not be a good approach since the person that you are sharing it with may not have Word installed. Or, you may not want to give the person the source document that can be edited, but rather a non-editable version of the document. PDFs are versatile because they maintain the layout of the original document, and allow people to share documents, presentations, invoices and so on in a way that can be viewed the same way on any device.
While PDFs are excellent for sharing, they can be challenging if you need to extract information from the document. Depending on how the PDF was created, the text that comprises the document may or may not be selectable. If the document was published to not allow updates, it is likely that the pages are actually images of each document page, which means that the text in the document doesn’t actually exist in the PDF. This can be problematic if you need to programmatically extract information from the PDF. Realistically, even if the PDF is saved with the text in the document, the unstructured nature of these types of documents make it very challenging to isolate the data that you are looking for, and pluck it out of the document. The term ‘unstructured text’ is an important one to understand, so I will explain exactly what that means.
Unstructured data is data that is formatted as prose, or sentences and paragraphs. It can be an essay, a contact form submission from your website, or an email that comes in from a client. In general, unstructured text does not have clear labels or hints that a software application could use in order to build a rule based algorithm to extract the data.
Now that you understand the differences between structured and unstructured data, I will explain how exactly information is extracted from unstructured documents, like PDFs.
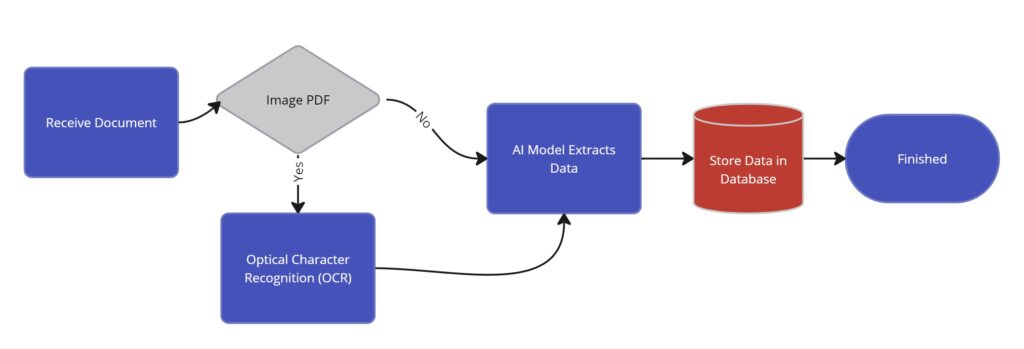
As shown in the diagram above, the steps are fairly straightforward in that there is only one decision that determines if the PDF is text or image based. If the PDF is image based, it runs the document through an Optical Character Recognition (OCR) microservice that tries to transcribe the text found in each page of the document. If the document is already text based, the pipeline simply sends the text pulled from the PDF, and runs it through the AI model that extracts the information. Once the information is extracted, the information is then sent to an application database, so that it can be persisted and so on.
While the above example is a bit abstract, the following example use-cases should get your wheels turning:
This article is just a brief overview of the process needed to extract data from PDF documents. While the overall concepts are straightforward, assembling the data, validating it, and training models with the data can be complex. Feel free to contact Wired Solutions if your organization needs help with their information extraction project.
 AI to Categorize Bank & Credit Card Transactions
AI to Categorize Bank & Credit Card Transactions